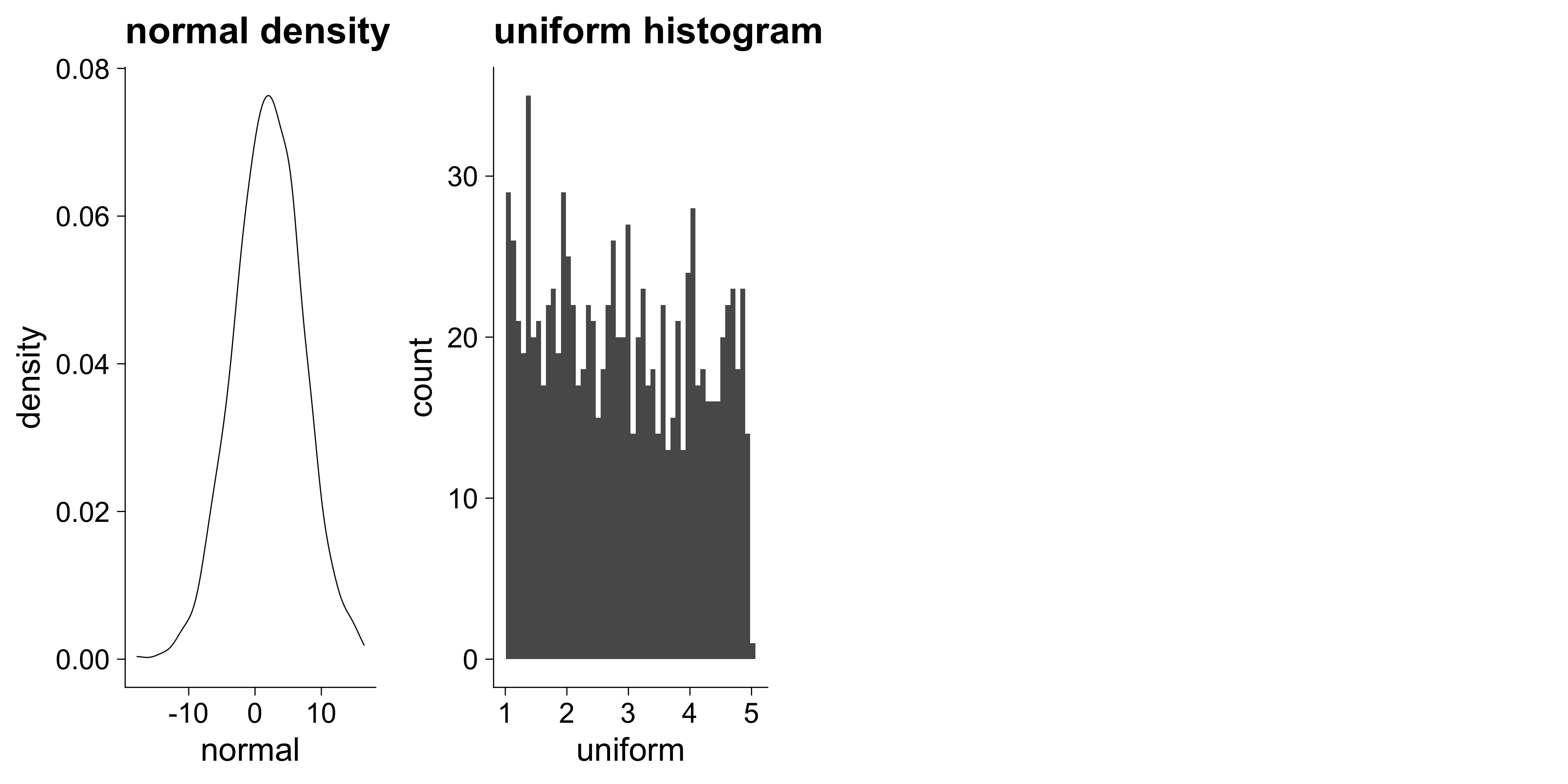
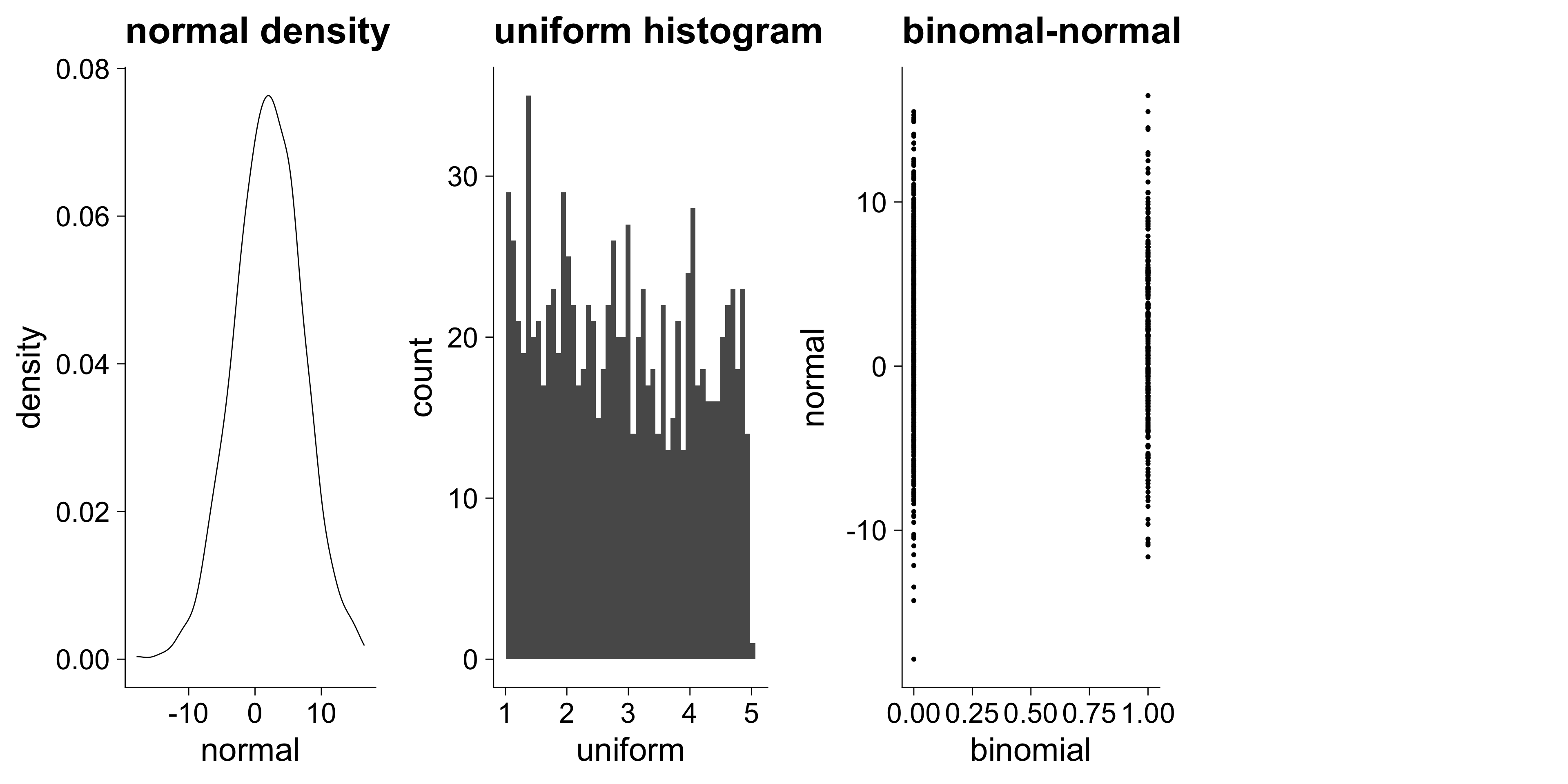
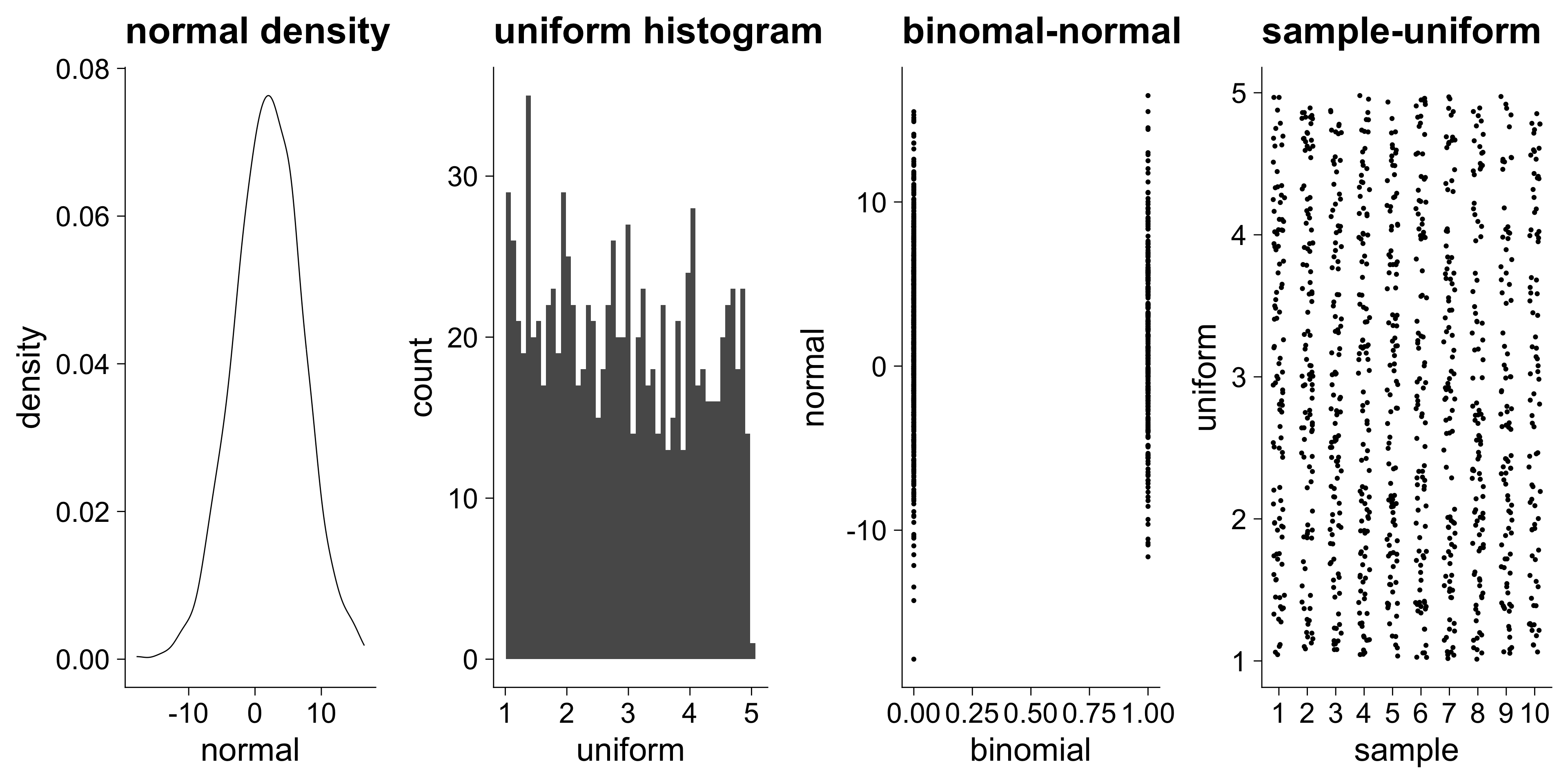
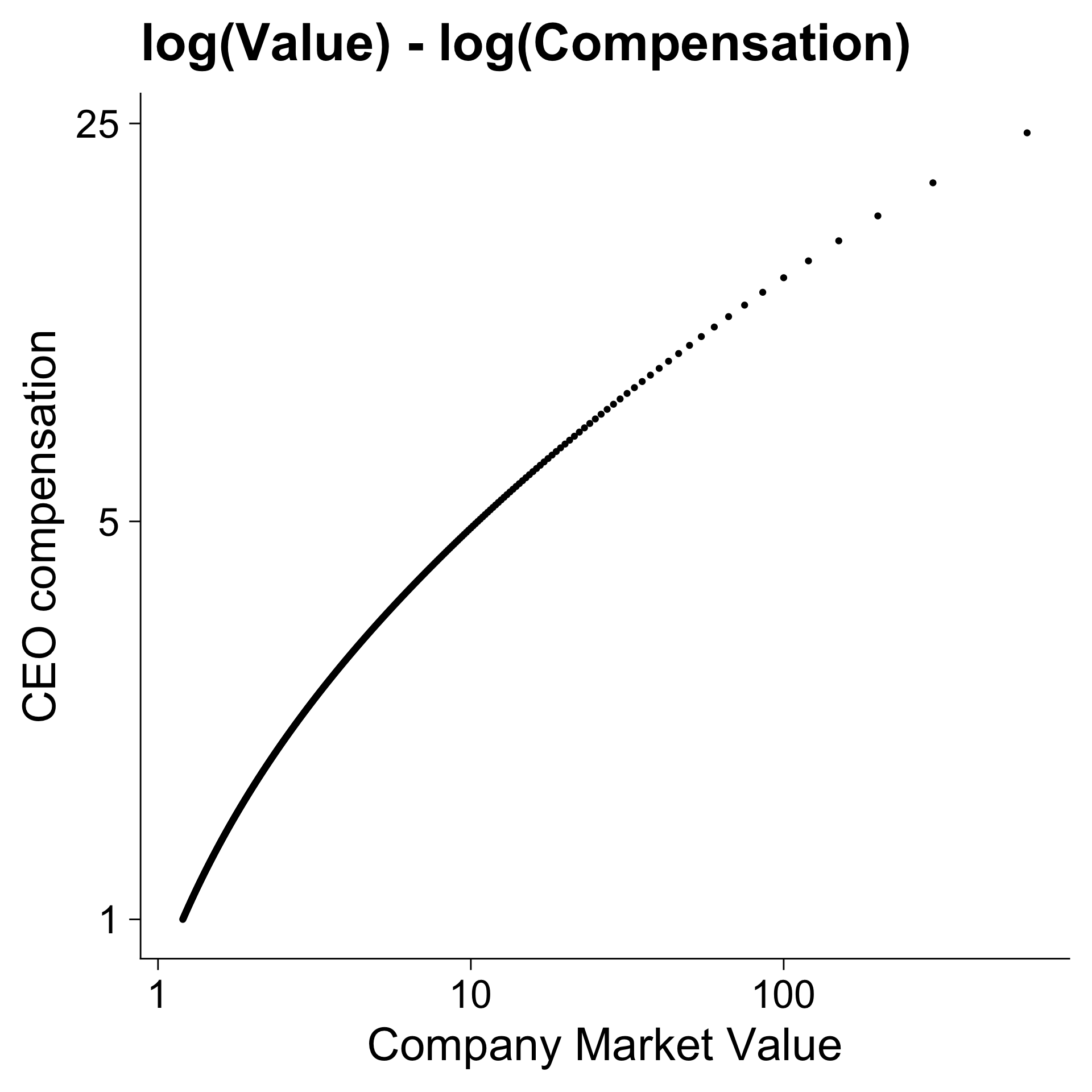
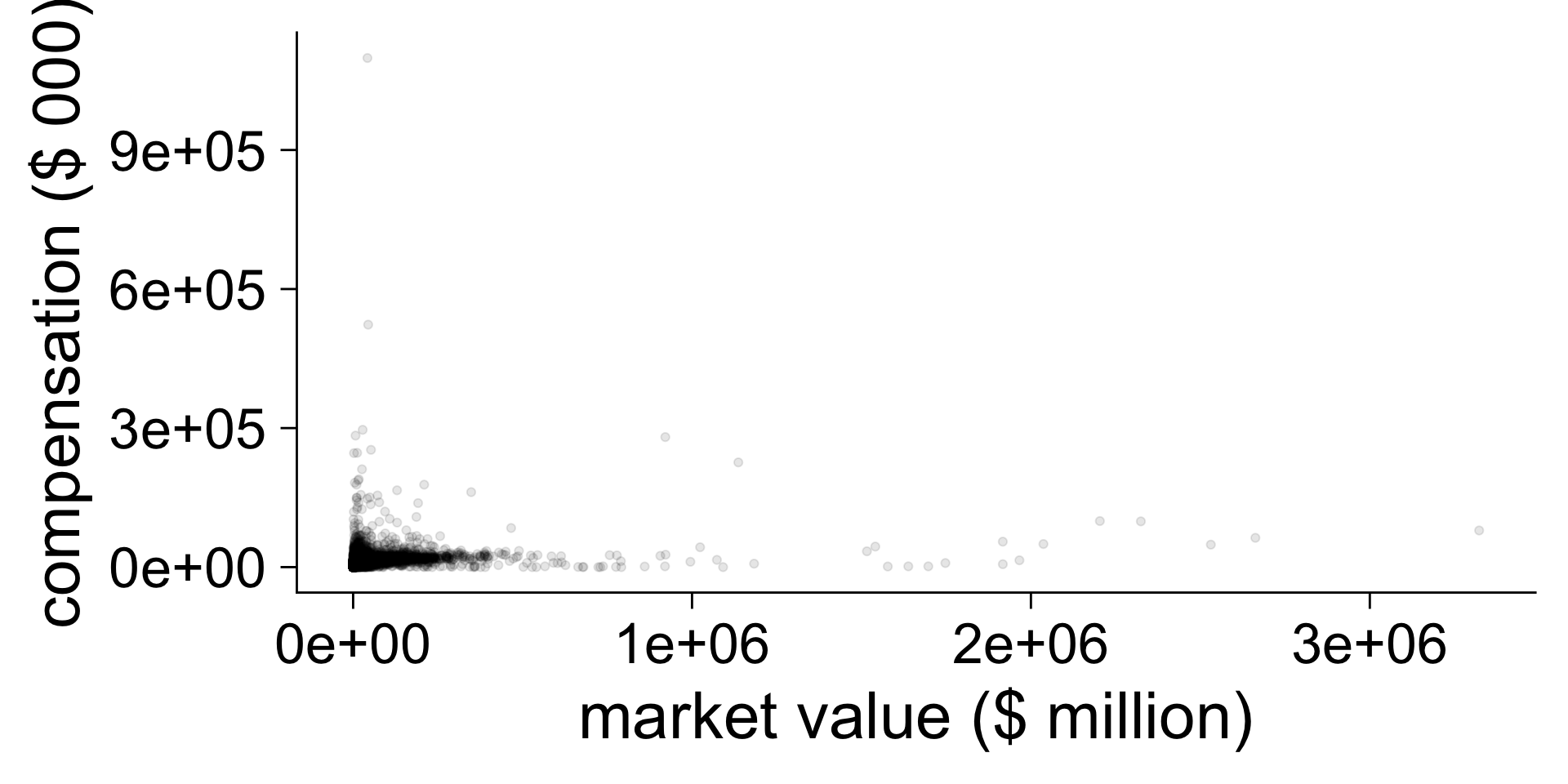
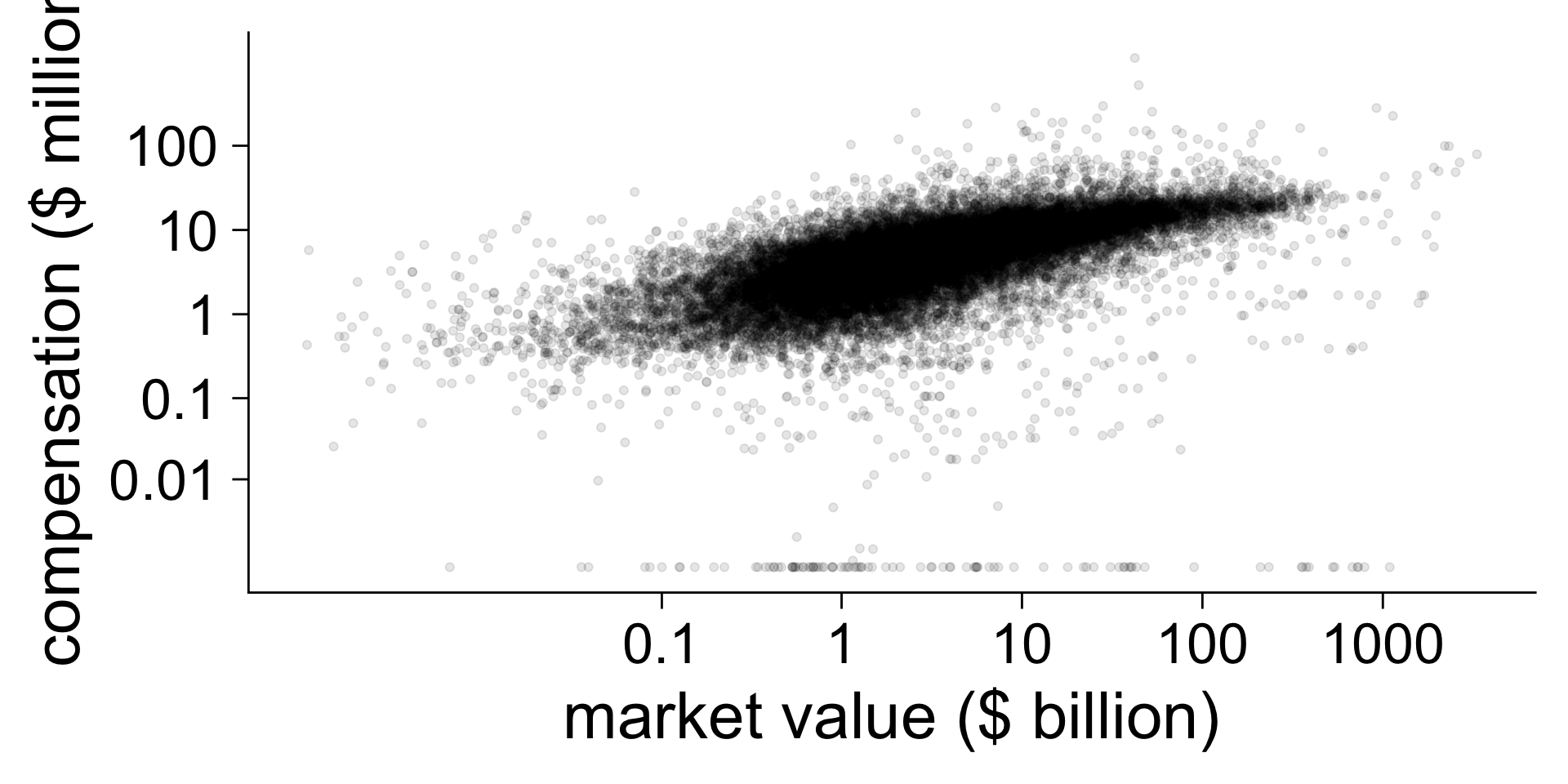
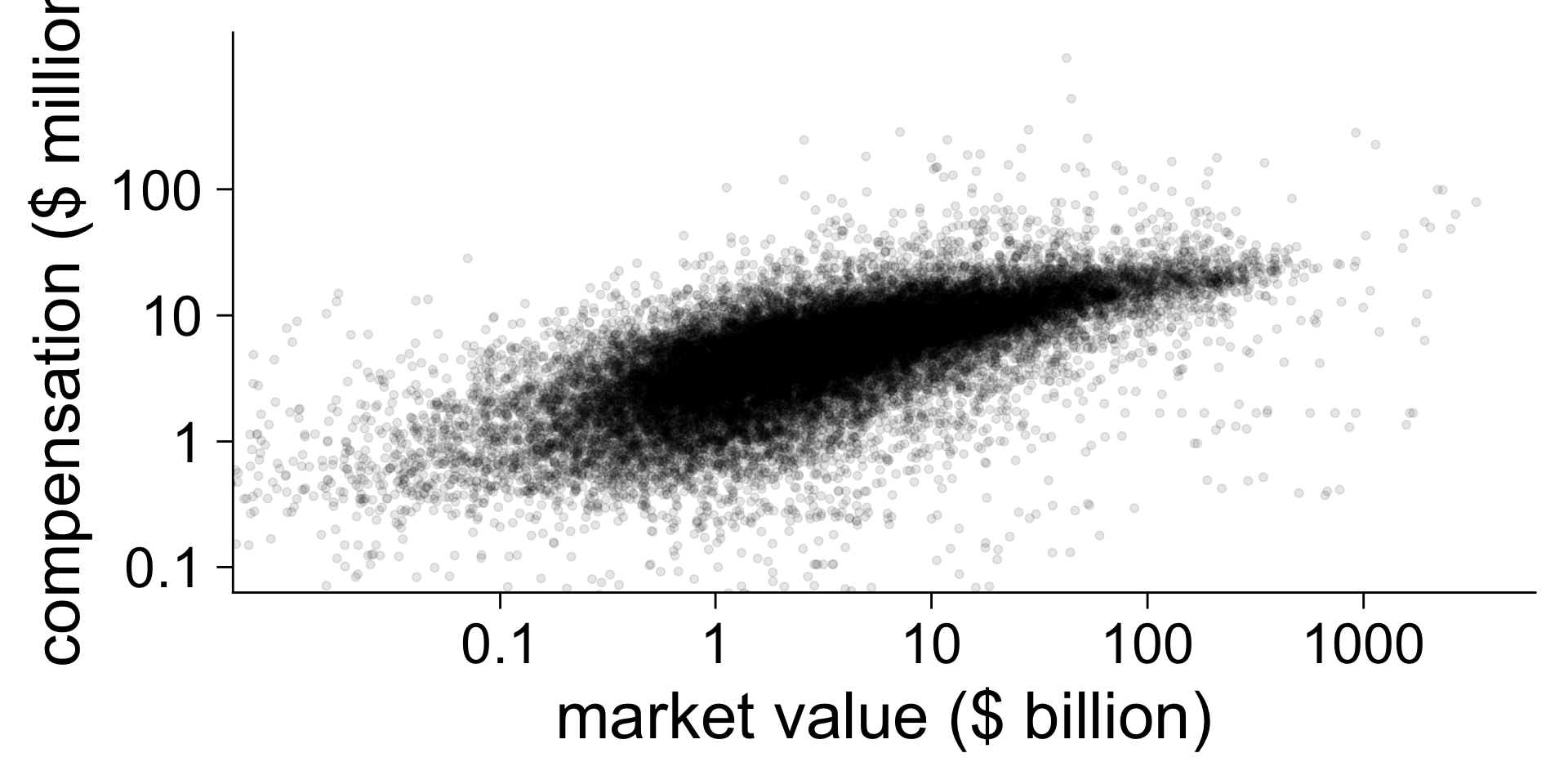
N <- 1000
random <- tibble(
normal = rnorm(N, mean = 2, sd = 5),
uniform = runif(N, min = 1, max = 5),
binomial = rbinom(N, size = 1, prob = .25),
sample = sample(1:10, size = N, replace = T)
)
glimpse(random)Rows: 1,000
Columns: 4
$ normal <dbl> 4.27858718, 2.37025621, 5.19396522, 6.442…
$ uniform <dbl> 1.160221, 2.228684, 2.274665, 1.177478, 3…
$ binomial <int> 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0,…
$ sample <int> 8, 3, 9, 10, 6, 7, 9, 4, 1, 2, 10, 3, 3, …