here() starts at /Users/stijnmasschelein/Library/CloudStorage/Dropbox/Teaching/lecturenotes/method_package
N <-1001gof_map <-c("nobs", "r.squared")set.seed(230383)
Interpretation
The problem
The problem with non-linear, generalised linear models is that the interpretation of the coefficients is more murky than in our linear models. In a linear model, we can interpret the coefficient, , of the variable easily. When is a continuous variable, we can interpret the coefficient as the increase in when increases by 1. When indicates whether an observation is in the treatment group () or in the control group (), the coefficient estimates the difference between the control and treatment group for .
Unfortunately, the non-linear transformation for the generalised linear models complicates the interpretation. Let’s illustrate this with an example where we know the true model for the probability that a firm has a female CEO () and the probability that the firm has a female CFO (). The true probabilities are given by the following logistic models.
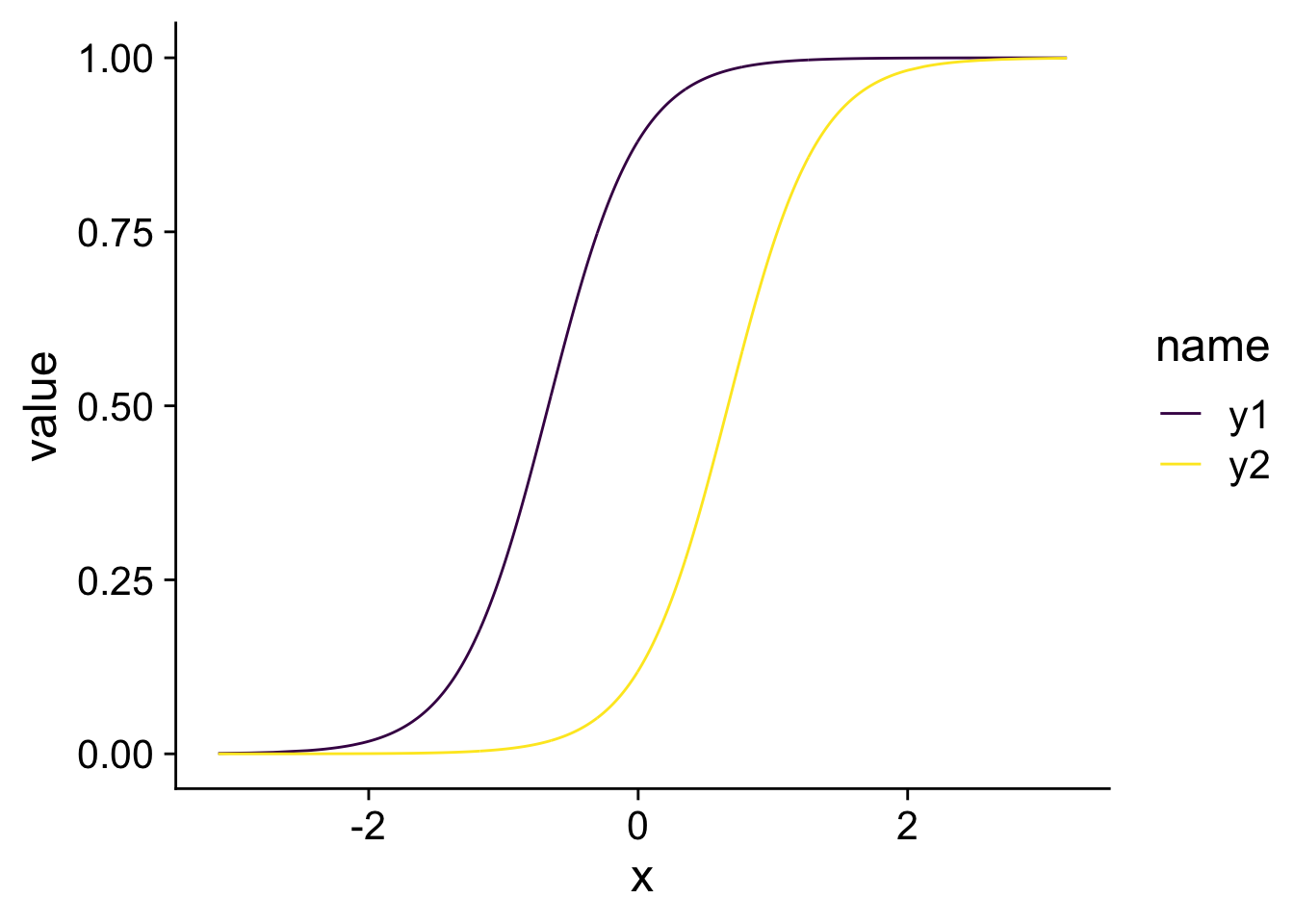
You can think of as a characteristic of the company that increases the likelihood of female executives in the company. A casual glance of the equations would give the impression that the effect of the characteristic on the CEOs and CFOs is the same because is the same in both equations. We can also plot the two probabilities as functions of and you can see that that one curve is just the other one shifted horizontally.
However, from the plots you can already see that firms at will see a larger increase in the probability of having a female CFO () than a female CEO () when increases. Because at most firms are already more likely to have a female CEO and thus the effect of cannot be very large. In other words, despite the fact that the two probabilities follow a very similar function, the effect of an increase in can be very different depending on the value of .
Another way to look at the problem is to think of as a policy that is either present () or not (). We can calculate the causal effect of the policy as follows.
Again, we see that the policy has a large effect (0.61) for and a small effect for (0.11).
Why does it matter?
There are a number of reasons when this will matter. First of all, the coefficient () does not directly map onto the causal effect. The same coefficient can lead to different causal effects depending on the value of and depending on other parts of the model (e.g. the intercept). That means that we cannot just rely on the coefficient.
Because the true effect depends on other parts of the model, generalised linear models make the use of fixed effects and robust standard errors more tricky as well. I am not going to go into the details of these issues but that is the overall problem with generalised linear model: the effect of each term is dependent on the other parts of the model.
There are two questions to ask whether this is a problem for your research question.
The first question is whether you are interested in predicting the variable or whether you are interested in estimating an effect on the variable . As I discussed in the introduction to machine learning, when we are mainly interested in prediction, the coefficients or effects are less important. In the case of predictions, we definitely want to use a model that does not allow to make impossible predictions (e.g. probabilities that are higher than 1).
The second question is whether we are interested in the effect on the linear scale () or on the transformed scale (). In the working example I have used so far, you probably would be interested in the transformed scale, i.e. the probability that the firm has a female CEO. In a lot of cases in accounting and finance, we would be interested directly in those probabilities e.g. the probability that a firm goes bankrupt, or discloses certain information. In contrast, studies in consumer finance or behavioural economics are more interested in the utility that consumers derive from certain interventions. While the utility is often unobserved, we can observe the consumers choices (e.g. which mortgage they choose). A typical approach is to model the unobserved utility on the a linear scale () and model the probability of a choice as a transformation of the utility (). In fact, the logistic transformation is the workhorse function in this literature. Finally, there is literature that prefers the linear scale for logistic models because they argue that we can interpret the effects on the log odds scale, . That is, the effect on the linear scale represents an effect on the relative probability.1 Betting markets often present winning probabilities as odds or relative probabilities.
Solution without controls
In the next, section I am going to assume that we are only interested in the effect on the probability scale and we would like to summarise the effect in one number. We will start with the simplest case where the variable of interest is a simple treatment () versus control (). We generate data according to the two functions above. In this simple case, it’s relatively easy to estimate the causal effects by just looking at the difference between the treatment and the control condition for both variables.
# A tibble: 2 × 3
x y1 y2
<int> <dbl> <dbl>
1 1 0.986 0.708
2 0 0.886 0.136
You can see that the differences are pretty close to the theoretical effects y1_effect = 0.11 and y2_effect = 0.61 that we calculated before.
Linear model
The next step is to figure out which regression approach gives us similar estimates. You can see that the OLS model, where we ignore that the outcome variable is restricted, gives us the estimate that we are interested in. To account for the distribution of the outcome variable, it is a good idea to specify se = "hetero". This way, feols uses a more robust estimation for the standard errors, accounting for the likely non-normal distribution of the error term.
The code also shows who you can run a logit or probit regression in R with the glm function. The main difference with the lm function is that you need to specify the family of models and the transformation link.
ols1 <-feols(y1 ~ x, data = solutions, se ="hetero")logit1 <-glm(y1 ~ x, data = solutions, family =binomial(link = logit))probit1 <-glm(y1 ~ x, data = solutions, family =binomial(link = probit))ols2 <-feols(y2 ~ x, data = solutions, se ="hetero")logit2 <-glm(y2 ~ x, data = solutions, family =binomial(link = logit))probit2 <-glm(y2 ~ x, data = solutions, family =binomial(link = probit))msummary(list(ols1 = ols1, logit1 = logit1, probit1 = probit1,ols2 = ols2, logit2 = logit2, probit2 = probit2),gof_map = gof_map, fmt =2)
ols1
logit1
probit1
ols2
logit2
probit2
(Intercept)
0.89
2.05
1.21
0.14
-1.85
-1.10
(0.01)
(0.14)
(0.07)
(0.02)
(0.13)
(0.07)
x
0.10
2.22
1.00
0.57
2.73
1.64
(0.02)
(0.41)
(0.16)
(0.03)
(0.16)
(0.09)
Num.Obs.
1001
1001
1001
1001
1001
1001
R2
0.043
0.333
Marginal Effects
You can get the best of both worlds in this simple case. We can use the non-linear models to give predictions on the probability scale with fitted and then look at the average between the treatment and the control group.
Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
0.1 0.0152 6.58 <0.001 34.3 0.0705 0.13
Term: x
Type: response
Comparison: 1 - 0
avg_comparisons(probit1, variables ="x")
Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
0.1 0.0152 6.58 <0.001 34.3 0.0705 0.13
Term: x
Type: response
Comparison: 1 - 0
Solution with controls
Things become more complicated when we introduce control variables. Remember, the effect of a variable is not constant in a non-linear model and it depends on other parts of the model. That means that the size of effect of x depends on the value of the control variable. Below, I simulate a dataset with a discrete control variable that takes three values (-1, 0, 1) with different probabilities. We can then run our three models and report them as before.
sol_controls <-tibble(x =rbinom(N, 1, 0.5),control =sample(c(-1, 0, 1), N, replace =TRUE,prob =c(0.5, 0.3, 0.2))) %>%mutate(y =rbinom(N, 1, plogis(-2+3* x +2* control)))ols_controls <-feols(y ~ x + control, data = sol_controls,se ="hetero")logit_controls <-glm(y ~ x + control, data = sol_controls,family =binomial(link = logit))probit_controls <-glm(y ~ x + control, data = sol_controls,family =binomial(link = probit))msummary(list(ols = ols_controls, logit = logit_controls,probit = probit_controls),gof_map = gof_map, fmt =2)
ols
logit
probit
(Intercept)
0.25
-2.00
-1.11
(0.02)
(0.17)
(0.09)
x
0.41
3.28
1.82
(0.02)
(0.25)
(0.13)
control
0.31
2.22
1.26
(0.01)
(0.15)
(0.08)
Num.Obs.
1001
1001
1001
R2
0.419
Let’s now calculate the effect for each value of the control variable 2. We use the same procedure but we just do it by control. We calculate the difference between the predicted probability for the control and treatment group. We also keep track of the number of observations in each cell. You can see in the printed intermediate calculation that the estimated effect differs for the three different values of the control variable. Because we want a one number summary, we can take the weighted (by number of observation) average of the effect to get the Average Marginal Effect.
There is another way of doing the calculation. We can also predict the probability assuming that an observation is in the treatment group (pred_x1) and assuming that an observation is in the control group (pred_x2). We can then calculate the Average Marginal Effect as the mean effect within the sample and we get a very similar result.
The last approach is what the avg_comparisons package does. One advantage of the last approach is that it scales better if we have multiple control variables and some of them are continuous. The predictions will account for the heterogeneity in the effect because of the differences in the control variables. The flip side of all of this is that the estimate really depends on the sample. A different sample, with radically different values for the control variables will have a different estimate for the effect of interest.
avg_comparisons(logit_controls, variables ="x")
Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
0.414 0.0218 19 <0.001 264.7 0.371 0.457
Term: x
Type: response
Comparison: 1 - 0
avg_comparisons(probit_controls, variables ="x")
Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
0.412 0.022 18.7 <0.001 257.2 0.369 0.455
Term: x
Type: response
Comparison: 1 - 0
Note
Note that the linear model ols_controls recovers the average marginal effect directly in the regression. If you are interested in a treatment effect of a treatment compared to a control group, in my opinion, you should just use a linear model with robustly estimated standard errors. The linear model makes it easy to incorporate fixed effects, deal with panel data, and expand the model to two-stage-least-squares or difference-in-differences while giving the estimate that you care about.
Warning
The average marginal effect calculation highlights that the effect that we estimate depends on the values of the control variables. As a result, we need to be careful about extrapolating the effect to different settings where the control variables might take different values.
Solution with continuous variable
The case of a continuous variable x is slightly more complicated because we already know that the relation between the outcome variable y and x is not perfectly linear. However, even with a continuous outcome variable, we also have to make the assumption of a linear relation. However, if we can make the assumption that the relation between y and x is roughly linear, the OLS estimate will be a good approximation of the average marginal effect as we can see below. As before, we can easily incorporate all the benefits of using feols while getting the estimate that we are targeting.
sol_continuous <-tibble(x =rnorm(N, 0, 1),control =rnorm(N, 0, 1)) %>%mutate(y =rbinom(N, 1, plogis(-2+3* x +2* control)))ols_continuous <-feols(y ~ x + control, data = sol_continuous,se ="hetero")logit_continuous <-glm(y ~ x + control, data = sol_continuous,family =binomial(link = logit))probit_continuous <-glm(y ~ x + control, data = sol_continuous,family =binomial(link = probit))msummary(list(ols = ols_continuous, logit = logit_continuous,probit = probit_continuous),gof_map = gof_map, fmt =2)
ols
logit
probit
(Intercept)
0.29
-1.99
-1.13
(0.01)
(0.15)
(0.08)
x
0.26
2.76
1.57
(0.01)
(0.19)
(0.10)
control
0.18
1.79
1.02
(0.01)
(0.14)
(0.08)
Num.Obs.
1001
1001
1001
R2
0.445
To get the average marginal effect with a continuous x, we use the avg_slopes function from marginaleffects. The function does something similar as avg_comparisons does for the discrete x. It will predict the probability of the outcome y for x and for x + 0.0013 and then take the difference. In other words, the function will approximate the estimate slope between y and x for each observations. The average marginal effect is again the average for the whole sample.
The fact that the calculation needs to be done for every observation can be a disadvantage of you have a lot of observations and a lot of effects to estimate.
avg_slopes(logit_continuous, variables ="x")
Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
0.261 0.00791 33 <0.001 791.3 0.246 0.277
Term: x
Type: response
Comparison: dY/dX
avg_slopes(probit_continuous, variables ="x")
Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
0.262 0.00782 33.5 <0.001 813.1 0.246 0.277
Term: x
Type: response
Comparison: dY/dX
All estimates point to the following effect: if x increases by .01, we expect the probability of y to increase by about .25% in our sample.
Further information
There is a lot more that can be done to with marginal effects and they can also be used to estimate non-linear effects in linear models. Andrew Heiss has a good overview of the theory and the marginaleffects package has excellent vignettes on how to implement the different possibilities.